The fastest WASM zlib
This year we started work on zlib-rs, an implementation of Zlib in Rust, with the goal of maintaining excellent performance while introducing memory safety.
Webassembly support was not on our initial roadmap, but when we got talking with Devolutions at this year's RustConf and they offered to support this milestone (thank you!), we were eager to get to work.
WASM SIMD
WASM has its own SIMD instructions these days. We know that SIMD is incredibly effective for the zlib algorithms, and were excited to use the WASM SIMD instructions. The C implementation that most of our code is based on zlib-ng does not (yet) use these instructions, so we have to figure out how to use them ourselves.
The core idea of SIMD (single instruction multiple data) is that we can process multiple inputs at once. So a basic loop like this:
pub fn slide_hash_chain_rust(table: &mut [u16], wsize: u16) {
for m in table.iter_mut() {
*m = m.saturating_sub(wsize);
}
}
can be written to process bigger chunks at once, in this case 8 16-bit values per iteration:
use core::arch::wasm32::v128;
use core::arch::wasm32::{u16x8_splat, u16x8_sub_sat, v128_load, v128_store};
#[target_feature(enable = "simd128")]
unsafe fn slide_hash_chain_wasm(table: &mut [u16], wsize: u16) {
let wsize_v128 = u16x8_splat(wsize);
for chunk in table.chunks_exact_mut(8) {
let chunk_ptr = chunk.as_mut_ptr() as *mut v128;
// Load the 128-bit value
let value = v128_load(chunk_ptr);
// Perform saturating subtraction
let result = u16x8_sub_sat(value, wsize_v128);
// Store the result back
v128_store(chunk_ptr, result);
}
}
The supported WASM SIMD instructions are relatively simple, and in comparison to e.g. AVX2 or NEON they still lack some features. Using the WASM SIMD functions in our code base was fairly straightforward.
Results
The results look good!
The baseline commit (before any WASM optimizations) is d693feb, the measurements are made using commit 94c1727, which includes all of our WASM optimizations:
- wasm: allow unaligned reads in
longest_match - wasm: SIMD
adler32 - wasm: SIMD
slide_hash - wasm: use wider loads/stores in
copy_match - wasm: SIMD
compare256
Decompression
| implementation | speedup (wall time) |
|---|---|
| baseline | -41.1% |
| miniz-oxide | -54.9% |
| zlib-ng | -25.3% |
Our optimizations made our implementation over 40% faster; we're now twice as fast as miniz-oxide, and significantly faster than zlib-ng.
Versus native
To get a better sense for how well we're doing, we can compare the WASM version to a native binary. Because WASM only has 128-bit registers, we include sse42 in this benchmark, which has the same limitation. The avx2 instruction set is available on most x86_64 systems today, so it is more representative of actual performance.
| instruction set | runtime (ms) | speedup (wall time) |
|---|---|---|
| sse42 | 257 | 0.0% |
| avx2 | 218 | +15.0% |
| WASM | 294 | -14.3% |
We see that WASM is still a bit slower than a native binary restricted to 128-bit SIMD. Using the wider 256-bit SIMD and fancier instructions of avx2 gives a nice boost over sse42.
Chunked decompression
The previous benchmark measures performance when all input is available, so most time is spent in a tight inner loop. But zlib is a streaming algorithm, which means we can feed it small chunks of input at a time. That exercises certain parts of the code much more, so it is important to benchmark this use case too.
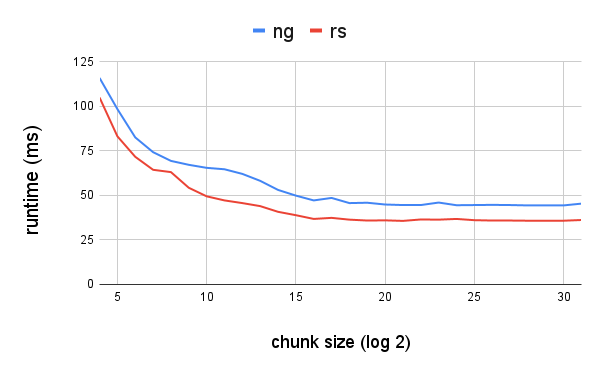
In this benchmark we feed the algorithm input in power-of-2 sized chunks (so a chunk size of 5 means chunks are 2 ** 5 = 32 bytes wide. We're faster than zlib-ng in all cases, the gap is between 10% to 20%.
Compression
Overall compression also sees a nice boost from SIMD, but for the medium algorithm (used for levels 3, 4, 5 and 6) it appears that zlib-rs isn't as efficient as zlib-ng today.
| compression level | runtime zlib-ng (ms) | runtime zlib-rs (ms) | speedup |
|---|---|---|---|
| 0 | 31.6 | 27 | 14.5% |
| 1 | 146.6 | 124.2 | 15.3% |
| 2 | 216 | 208 | 3.7% |
| 3 | 250 | 260 | -4.0% |
| 4 | 280 | 280 | 0.0% |
| 5 | 304 | 308 | -1.3% |
| 6 | 354 | 346 | 2.2% |
| 7 | 470 | 414 | 11.9% |
| 8 | 584 | 510 | 12.7% |
| 9 | 678 | 574 | 15.3% |
Conclusion
As far as we know, we are the fastest WASM zlib implementation today.
You can find our raw data and more information on the methodology and tools here.
Our recent 0.4.0 release includes WASM support and was audited by ISRG. The easiest way to use zlib-rs today is via the flate2 crate with the "zlib-rs" feature.